PACKAGES
FactoMineR | factoextra
Cluster: HCPC¶
Package FactoMineR
L’HCPC (Hierarchical Clustering on Principal Components [1]) combina tre metodi di analisi multivariata:
- Principal Components (PCA)
- Hierarchical Clustering (HC)
- Partition Clustering (k-means)
Il metodo HCPC si compone sommariamente delle seguenti fasi:
- Esecuzione l’analisi delle componenti principali (PCA). E’ possibile scegliere il numero di dimensioni da considerare.
- Esecuzione l’analisi di cluster gerarchica con il metodo di Ward.
- Scelta del numero di cluster.
- Esecuzione della cluster K-means per migliorare e consolidare la partizione iniziale del’HC. La partizione finale può essere differente dalla prima partizione.
r.hcpc esegue un’analisi di Hierarchical Clustering on Principal Components.
Argomenti: [2]
- varlist: l’elenco delle variabili da utilizzare nell’analisi
- PCA:
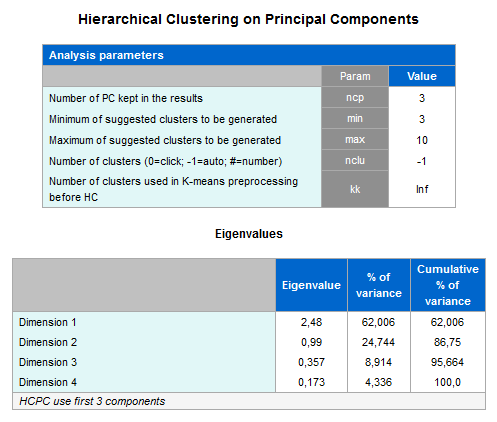
- :ncp => num: il numero di componenti principali da utilizzare nell’analisi
- :rsup => indexes: un array o un range con i numeri di indice delle righe supplementari
- :vsup => varlist: un array con i nomi delle variabili supplementari quantitative
- :qsup => varlist: un array con i nomi delle variabili supplementari quanlitative
- :weight => varname: il nome di una variabile di ponderazione
- HC:
- :nclu => num: il numero dei cluster da generare: 0 = l’utente determina il numero cliccando sul dendogramma; -1 (default) = trova automaticamente il numero di cluster ottimale; num = imposta un numero di cluster specifico
- :min => num: il numero minimo suggerito di cluster da generare
- :max => num: il numero massimo suggerito di cluster da generare
- :cluster => name: il nome della variabile cluster
- :kk => num: se specificato, esegue un partizionamento con metodo k-means con il numero di cluster indicato. I cluster ottenuti vengono poi utilizzati dalla cluster gerarchica al posto delle osservazioni originali. La successiva fase di consolidamento con k-means non viene eseguita. E’ utile quando i numero di record è troppo elevato per la cluster gerarchica.Il numero di cluster da indicare deve essere considerevole.
Tabelle disponibili:
- :analysis: riepilogo dei parametri dell’analisi
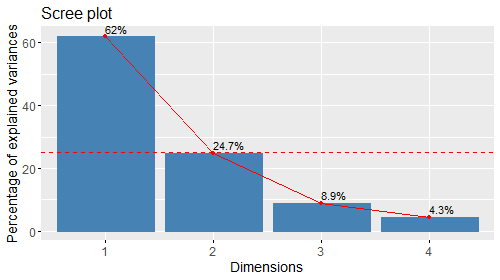
- :eig: gli autovalori
- :coord: le coordinate delle variabili
- :load: i loading delle variabili
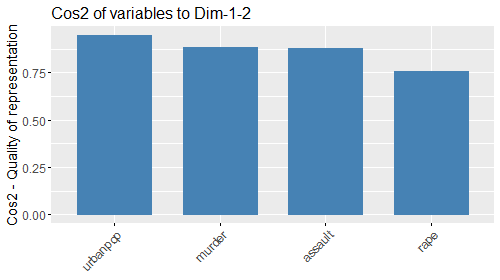
- :cos2: cos2 delle variabili
- :contr: i contributi delle variabili
- :clus: la distribuzione dei cluster
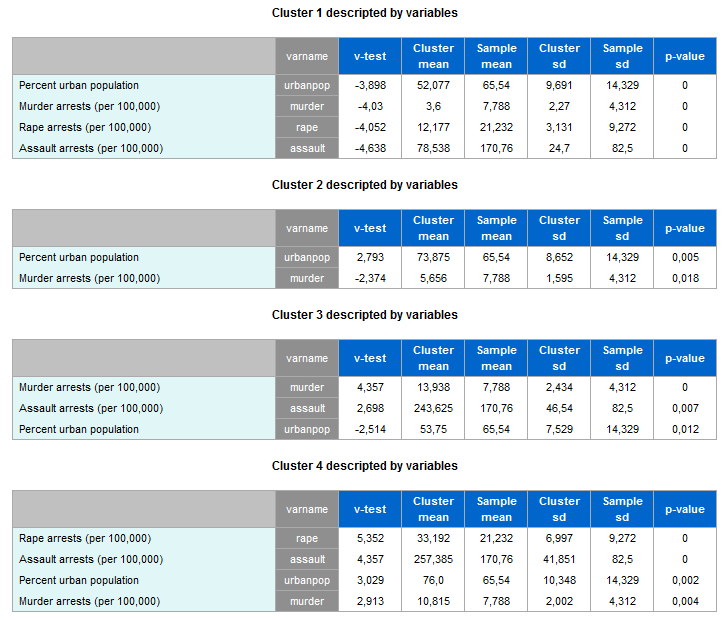
- :descrv: i cluster descritti dalle variabili
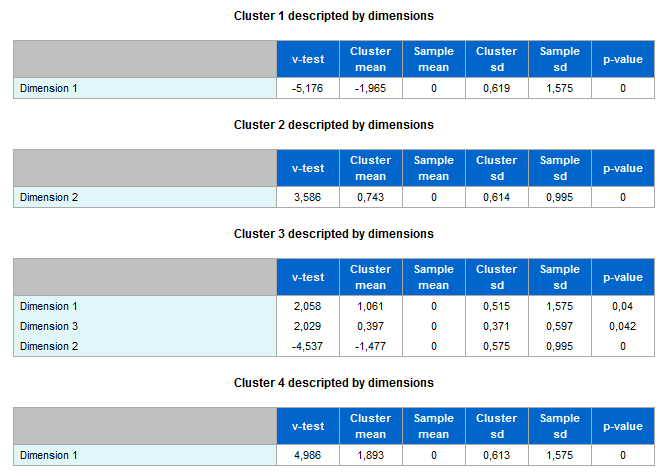
- :descrd: i cluster descritti dalle dimensioni
Grafici disponibili:
- :eig: Eigenvalues Scree plot
- :cos2: Cos2 delle variabili sulle dimensioni 1 e 2
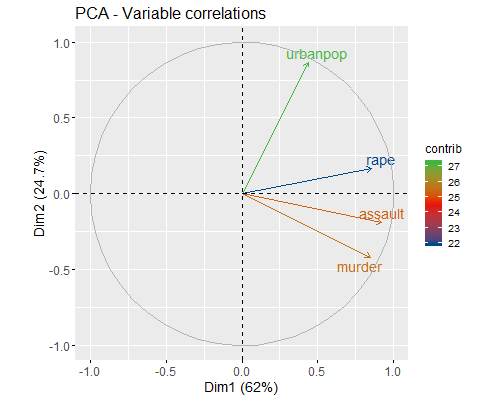
- :pca: PCA: correlazione delle variabili per contributi
- :contr1[..5]: Contributi delle variabili sulla dimensione 1[..5]
- :fctmap: I cluster consolidati dalla cluster k-means sul piano delle prime due componenti principali
- :biplot: Biplot dell’analisi PCA con variabili e individui suddivisi per cluster
- Non generato di default:
- :dend: Dendogramma dei cluster suggeriti dalla HC (lento con tanti casi)
1 2 | model = [:murder, :assault, :urbanpop, :rape]
r.hcpc model, :rownames => :state, :weight => :peso, :plots => [:default, :dend]
|


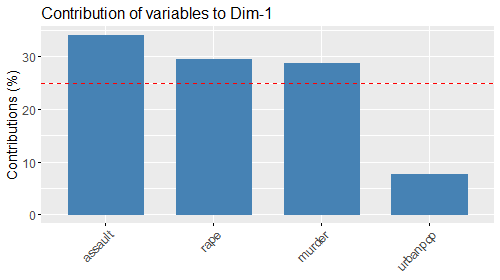
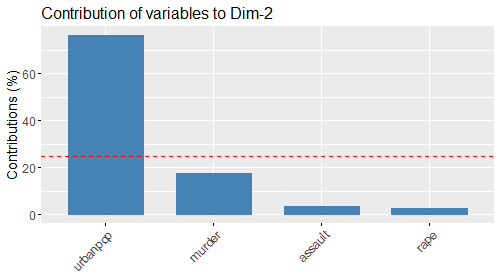
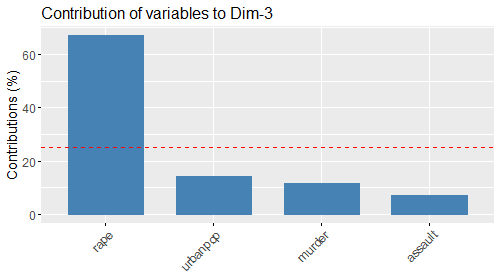
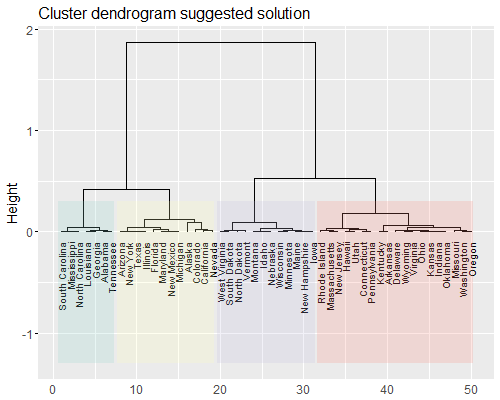



Note
| [1] | Husson, François, J. Josse, and Pagès J. 2010 - Principal Component Methods - Hierarchical Clustering - Partitional Clustering: Why Would We Need to Choose for Visualizing Data?. Husson, François Hierarchical clustering |
| [2] | Consultare Analisi per l’elenco dei parametri generali. |