PACKAGES
randomForest | caret | gplots
Random Forest¶
r.rforest genera un modello di Random Forest aggregando un grande numero di alberi decisionali di classificazione o di regressione.
Ciascun albero viene generato a partire da un sample estratto tramite bootstrap e utilizzando ad ogni split un sample random di predittori.
I dati possono essere divisi in un sample di training per la stima del modello e uno di holdout per la validazione.
Argomenti: [1]
- varname => varlist: un hash con la variabile dipendente e l’elenco di predittori
- :train: la percentuale di casi da estrarre per il training sample (default 0.7). Se 1 tutti i casi verranno usati come training sample e nessuno cone holdout sample
- :ntree: il numero di alberi da generare (default 500)
- :mtry: il numero di variabili da estrarre ad ogni split (default sqrt(p) nel caso di classificazione, p/3 nel caso di regressione)
- :replace => true|false: se l’estrazione dei sample deve essere fatta con reinserimento dei casi (default true)
- :na => :fail|:omit: comportamento in caso di valori mancanti: :fail genera un errore; :omit esclude il record (default :fail)
- :seed: un seed per replicare l’analisi
Tabelle disponibili:
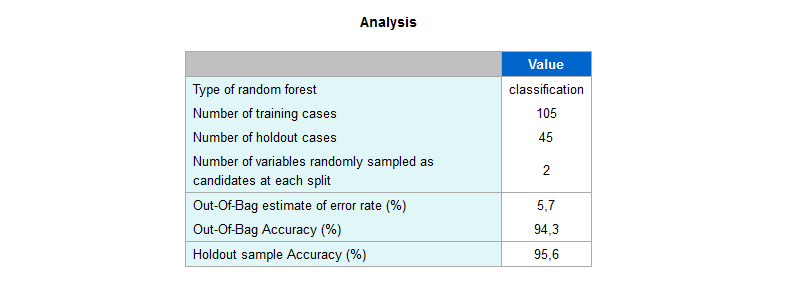
- :analysis: riepilogo dei parametri dell’analisi
- :rf: riepilogo delle statistiche dell’analisi
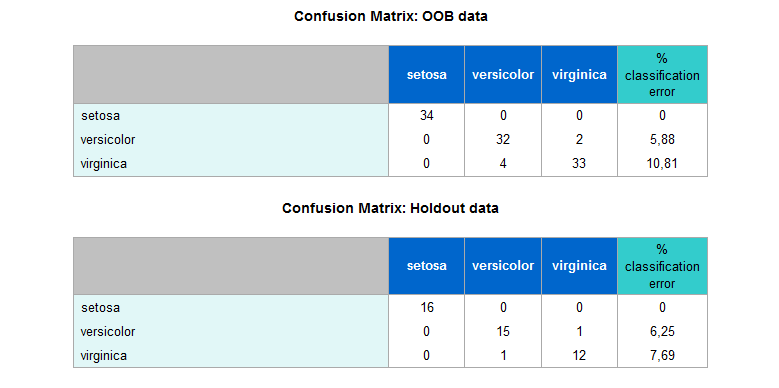
- :confusion: matrice di confusione (solo per classificazione)
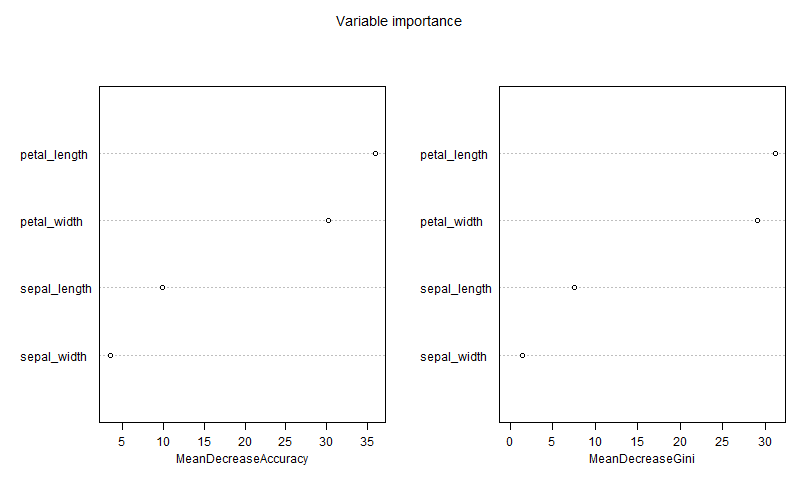
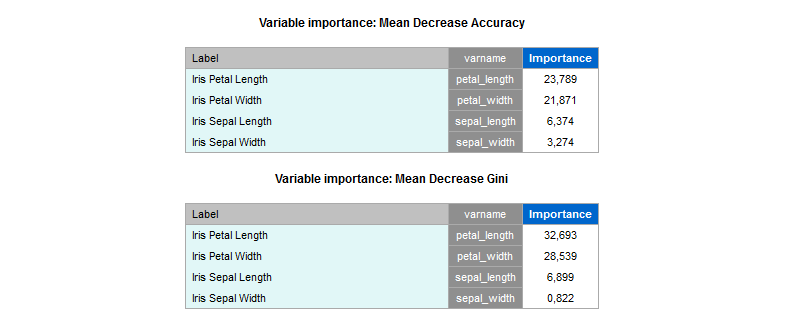
- :imp: importanza relativa delle variabili
Grafici disponibili:
- :error: andamento del tasso di errore per numero di alberi
- :varimp: importanza relativa delle variabili
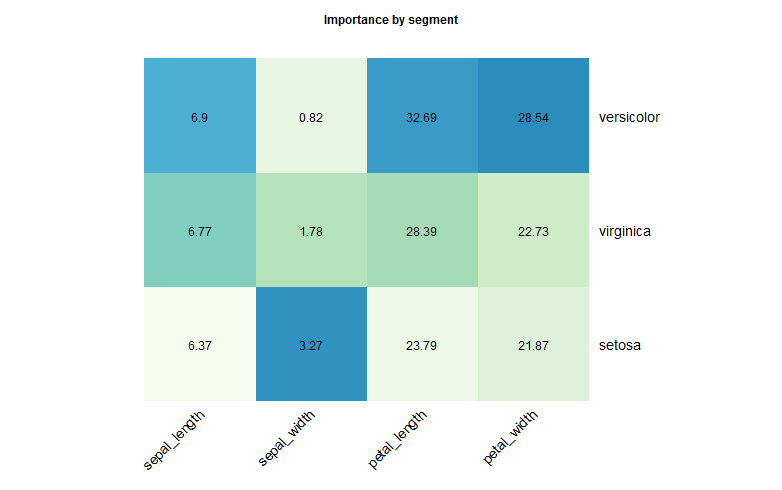
- :heatmap: heat map delle importanze delle variabili per segmento (solo per classificazione)
- :clusplot: clusterplot dei valori predetti sul campione holdout (solo per classificazione)
1 | r.rforest :species => [:sepal_length, :sepal_width, :petal_length, :petal_width]
|



Note
| [1] | Consultare Analisi per l’elenco dei parametri generali. |